2 - Introdução aos Dados de Investigação
Aqui serão introduzidos alguns conceitos chave nesta temática. Esta breve introdução deverá facilitar a compreensão do ciclo de dados de investigação, apresentado na secção seguinte.
Dados de Investigação: o que são
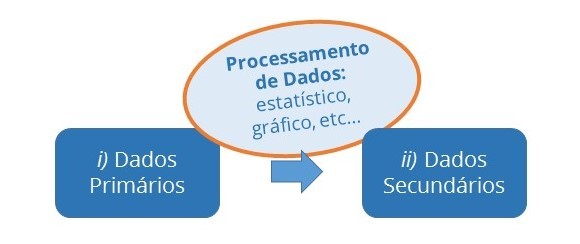
No contexto do RCAAP e deste Kit, consideram-se dados de investigação científica, todos e quaisquer dados de investigação[1] que sejam produto direto ou indireto do processo de investigação científica e por isso necessários para a validação de resultados científicos. A título exemplar e baseado no glossário publicado pelo consórcio CASRAI[2] destacamos observações ou registos numéricos, textuais, imagens e vídeos, nos mais variados formatos digitais, enquanto exemplos de dados de investigação. Assim, podem distinguir-se dois tipos diferentes de dados de acordo com o seu grau de processamento, primários e secundários, conforme abaixo detalhado:
i) primários: dados de investigação obtidos diretamente do processo de investigação, instrumento ou metodologia científica, sem que tenham sofrido qualquer processamento ou transformação (p. ex.: entrevista áudio/vídeo sem edição, dados de gerados por um instrumento de medição sem que tenham sofrido processamento).
ii) secundários: dados resultantes da interpretação, processamento ou transformação de dados primários (p. ex.: entrevista áudio/vídeo após edição, dados de gerados por um instrumento de medição sem após processamento ou aplicação de modelos estatísticos).
Dados de investigação fazem portanto parte integrante de qualquer processo de investigação científica, e como tal, são base para todo o “output científico”. Em seguida, é analisado em detalhe o ciclo de dados de investigação, de forma a ilustrar a integração e gestão dos mesmos, no processo de investigação científica.
É importante notar que, ainda possa ser útil, a distinção entre dados primários ou secundários não é livre de ambiguidades: diferentes disciplinas poderão ter noções diferentes acerca de um mesmo conjunto de dados.
Big-Data vs. dados “long-tail”
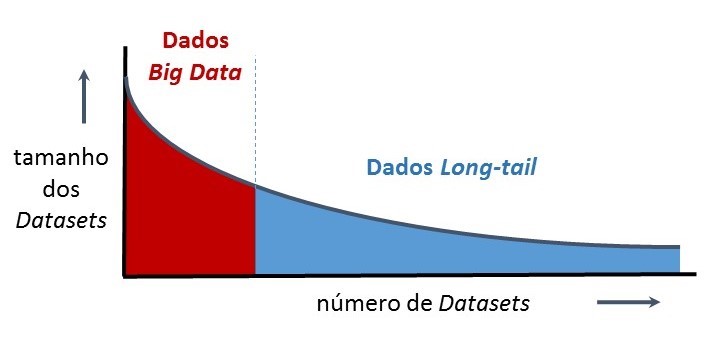
Para além da distinção relativa ao grau de processamento (dados primários ou secundários) é também relevante distinguir diferentes tipos de dados de investigação, nomeadamente clarificar os conceitos “dados big-data” e “dados long-tail”, uma vez que as suas características implicam diferentes medidas para a gestão de dados.
A figura seguinte ilustra esquematicamente a distribuição do tamanho de datasets produzidos em investigação científica, pelo respetivo número de datasets. Existem várias fontes,[3],[4] que indicam esta como sendo a distribuição característica da produção atual de dados de investigação, ou seja: a minoria dos conjuntos de dados (datasets), corresponde ao maior volume de informação (big-data, superfície a vermelho); Inversamente, a larga maioria dos dados de investigação (datasets) corresponde à “cauda-longa” da distribuição (long-tail, superfície a azul).
A tabela seguinte procura comparar as características destes tipos de dados de investigação, salientando os principais aspetos de relevância para a sua gestão e preservação.
|
Tipo |
Big-Data |
Dados Long-Tail |
|
Homogeneidade |
homogéneos |
heterógenos |
|
Volume dos Datasets |
grande |
pequeno |
|
Diretrizes e normas |
estabelecidas |
únicas ou inexistentes |
|
Curadoria |
centralizada |
individual |
|
Tipo de Repositórios |
disciplinar |
institucional |
|
Reutilização dos Dados |
frequente |
rara |
Tabela 1: Tabela-resumo das características de dados de investigação big-data e dados long‑tail.[5]
A implicação prática destes conceitos e de tal distribuição é o facto da maioria dos dados de investigação – Dados “long-tail” - constituírem o maior desafio em termos de planeamento, gestão, preservação e reutilização, devido à sua natureza heterogénea e singular.
Preservação Digital
Por preservação digital entende-se, neste contexto, um conjunto de medidas e infraestruturas necessárias para garantir a integridade de dados digitais a longo-termo, por vários anos e idealmente por tempo o termo indeterminado (ad eternum). Inclui estratégias de backups regulares, algoritmos de sincronização, migração para outros formatos físicos, entre outras medidas. A título complementar inclui-se aqui também a definição do programa Ciência Aberta3, que define “preservação”[6] como “um termo genérico que designa o conjunto de medidas a empreender para garantir a preservação da integridade dos documentos e dos seus conteúdos, em manter o acesso eletrónico e em assegurar a legibilidade e a perenidade dos seus conteúdos durante um longo período de tempo”.
[1] No contexto do RCAAP enquanto repositório digital, não são considerados dados ou documentos em formato analógico.
[2] “Facts, measurements, recordings, records, or observations about the world collected by scientists and others, with a minimum of contextual interpretation. Data may be in any format or medium taking the form of writings, notes, numbers, symbols, text, images, films, video, sound recordings, pictorial reproductions, drawings, designs or other graphical representations, procedural manuals, forms, diagrams, work flow charts, equipment descriptions, data files, data processing algorithms, or statistical records.”; in: http://dictionary.casrai.org/Data
[3] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4728080/; Nat Neurosci. 2014 Nov; 17(11): pp. 1442–1447; doi: 10.1038/nn.3838
[4] http://science.sciencemag.org/content/331/6018/692; Science 11 Feb 2011: Vol. 331, Issue 6018, pp. 692-693; DOI: 10.1126/science.331.6018.692
[5] Adaptado do artigo Shedding Light on the Dark Data in the Long Tail of Science, P. Bryan Heidorn. 2008